Содержание
Мой личный опыт восстановления старых фотографий с помощью нейросетей / Хабр
Немного о происхождении фотографий. Напомню, что 26 Апреля 1986 года произошла катастрофа на Чернобыльской АЭС.
Но мало кто знает, что радиоактивное облако распространилось на тысячи километров. К сожалению, это затронуло и деревню моей бабушки недалеко от Гомеля. Жителей эвакуировали далеко не сразу, но когда пришло время уезжать, то фотографии, которые были приклеены на стене пришлось отклеивать варварским способом. Время потрепало эти фотографии, но попробуем восcтановить.
Для примера я взял только две фотографии. На первой, мой двоюродный брат бабушки и какой-то человек на лошади. На второй — мой прадедушка.
Как можно дать вторую жизнь этим фотографиям?
Осторожно, большие фотографии!
Есть множество способов восстановить потрёпанные фотографии.
Можно сделать это вручную в любом удобном графическом редакторе. Можно выбрать онлайн сервисы для восстановления, но всегда есть ограничения. Я же решил найти несколько инструментов на основе нейронных сетей, которые можно запустить на домашнем ПК.
Я же решил найти несколько инструментов на основе нейронных сетей, которые можно запустить на домашнем ПК.
В этой статье я хочу поделиться своим детским опытом, как бесплатно восстановил несколько фотографий.
Сразу условимся, что статья носит чисто ознакомительный характер.
Я лично тестировал на своем ноутбуке 7 летней давности:
i7-5700HQ
16 ГБ оперативной памяти
SSD диск
Опционально можно использовать видео карту NVIDIA, но моя GTX960M устарела, и я её не использовал. Для запуска с видеокартой в каждом скрипте есть опция GPU.
Windows 10/11
На мой взгляд проще всего это сделать с помощью подсистемы Linux в Windows 10 или 11.
1. Установка
Для упрощения записал видео инструкцию.
Специально для тестов я написал небольшой скрипт
Открываем терминал в Ubuntu и вводим
git clone https://github.com/SergeiSOficial/AiPhoto.git cd AiPhoto sudo chmod +x *.sh
Далее запускаем установку
./setup.sh
Во время установки откроется папка с проектом.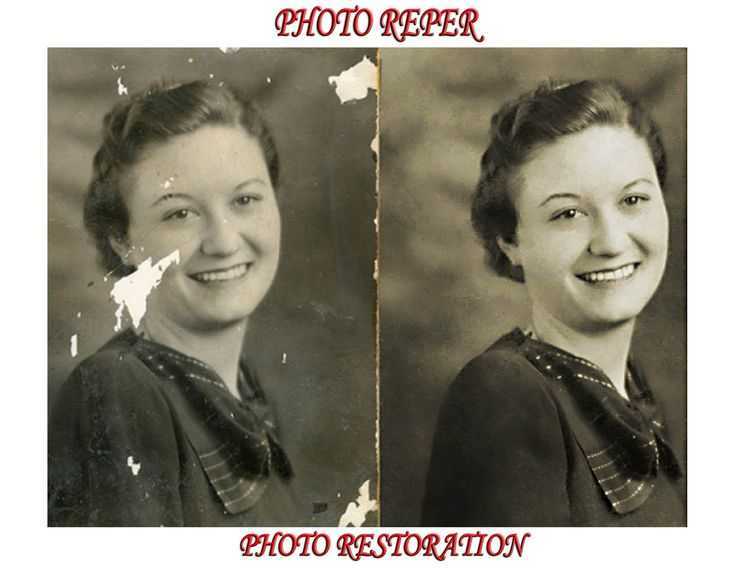 Начальные фотографии складываем в input, в папке output будем искать результаты. Важно, что файлы должны быть не слишком большими или иметь достаточный объем оперативной памяти.
Начальные фотографии складываем в input, в папке output будем искать результаты. Важно, что файлы должны быть не слишком большими или иметь достаточный объем оперативной памяти.
На моем ноутбуке с интернетом 30 Мбит/с вся установка заняла примерно 30 минут.
2.Запуск
Почему алгоритма три?
Bringing Old Photo Back to Life неплохо убирает трещины, но недостаточно хорошо восстанавливает лица. GFPGAN хорошо справляется с людьми, но требует чистую фотографию. DeOldify хорошо разукрашивает.
Запускаем алгоритм от компании Майкрософт
cd AutoDeOldifyLocal/DeOldify/ conda activate deoldify cd ../../Bringing-Old-Photos-Back-to-Life python run.py --input_folder ../input --output_folder ../output/BOPBTL/ --GPU -1 --with_scratch --HR
После этого запускаем алгоритм от китайской компании GFPGAN
cd ../GFPGAN python inference_gfpgan.py -i ../output/BOPBTL/stage_1_restore_output/restored_image -o ../output/GFPGAN/ -v 1.3 -s 2
И в конце запускаем разукрашивание
cd ../AutoDeOldifyLocal/DeOldify/ python RunColorizer.py --input_folder ../../output/GFPGAN/restored_imgs --GPU -1 --output_folder ../../output/DeOldify/ --artistic True cd ../../
 ./AutoDeOldifyLocal/DeOldify/
python RunColorizer.py --input_folder ../../output/GFPGAN/restored_imgs --GPU -1 --output_folder ../../output/DeOldify/ --artistic True
cd ../../
./AutoDeOldifyLocal/DeOldify/
python RunColorizer.py --input_folder ../../output/GFPGAN/restored_imgs --GPU -1 --output_folder ../../output/DeOldify/ --artistic True
cd ../../Все три алгоритма выполнялись примерно 10 минут.
Конечно, алгоритмы работают неидеально, но результаты, лично для меня, любопытные.
Ссылка на репозиторий со скриптами для установки и запуска.
Еще раз ссылка для скачивания видео.
Надеюсь, статья будет полезна. Но в любом случае оставляйте комментарии.
10 нейросетей, для улучшения качество фото — Нейронный центр на vc.ru
Существует множество нейросетей, которые используются для улучшения качества фотографий. Они помогают устранить шумы, повысить резкость и насыщенность цветов, а также восстановить детали, которые могут быть утрачены при сжатии или обработке изображения. В этой статье мы рассмотрим 10 наиболее эффективных нейросетей, которые помогают улучшить качество фото.
- SRGAN SRGAN — это нейросеть, которая используется для увеличения разрешения изображений. Она использует технологию глубокого обучения, которая позволяет повышать качество изображения, не увеличивая его размер.
- ESRGAN ESRGAN — это улучшенная версия SRGAN, которая использует технологии глубокого обучения и нейросетей для создания более качественных изображений с высоким разрешением.
- DeepRemaster — это нейросеть, которая используется для восстановления качества старых фотографий и видео. Она использует глубокое обучение и нейросети для восстановления деталей и цветовых схем.
- DeepFill — это нейросеть, которая используется для заполнения пропущенных областей на фотографиях. Она может использоваться для восстановления деталей в областях, где информация потеряна, или для удаления объектов из изображения.
- DeOldify — это нейросеть, которая используется для восстановления цвета на черно-белых фотографиях. Она может использоваться для восстановления старых фотографий или для создания цветных версий черно-белых изображений.
- StyleGAN — это нейросеть, которая используется для создания реалистичных изображений лиц, объектов и сцен. Она использует технологии глубокого обучения, чтобы создавать уникальные и качественные изображения.
- CycleGAN — это нейросеть, которая используется для переноса стиля с одного изображения на другое. Она может использоваться для создания уникальных эффектов на изображениях или для изменения фона или окружения на фотографиях.
- Neural Style Transfer — это нейросеть, которая используется для создания изображений с уникальным стилем. Она может использоваться для превращения фотографий в произведения искусства, добавления текстур и эффектов, а также для создания уникальных графических элементов.
Colorizer — это нейросеть, которая используется для автоматического раскрашивания черно-белых фотографий. Она использует глубокое обучение и нейросети для восстановления цвета на изображениях.
Noise2 — это нейросеть, которая используется для устранения шума на фотографиях. Она может использоваться для удаления шумовых элементов на изображениях, таких как артефакты сжатия, сигналы и помехи.
Эти 10 нейросетей представляют собой только малую часть тех, которые используются для улучшения качества фотографий. Каждая из них имеет свои особенности и применения, и выбор наиболее подходящей зависит от конкретной задачи и требований к изображению. Однако, все они отлично справляются с улучшением качества фотографий и помогают создавать более качественные и профессиональные изображения.
 Она использует технологию глубокого обучения, которая позволяет повышать качество изображения, не увеличивая его размер.
Она использует технологию глубокого обучения, которая позволяет повышать качество изображения, не увеличивая его размер.

ChatGPT — это простой и удобный способ общения, но доступ к нему может быть ограничен.
Решение — использование телеграм-бота. Подключиться к ChatGPT теперь проще простого — просто нажмите на ссылку и наслаждайтесь бесплатным чатом!
104
просмотров
Раскрашивание и восстановление старых изображений с помощью глубокого обучения
Раскрашивание черно-белых изображений с помощью глубокого обучения стало впечатляющей демонстрацией реального применения нейронных сетей в нашей жизни.![]()
Джейсон Антик решил сделать еще один шаг вперед в области раскрашивания с помощью нейронных сетей. Его недавний проект глубокого обучения DeOldify не только раскрашивает изображения, но и восстанавливает их с потрясающими результатами:
изображений, раскрашенных DeOldify: «Воины-самураи около 1860-х годов». Изображения, раскрашенные DeOldify: «Женщина из Техаса в 1938 году»
Вы также можете добиться впечатляющих результатов на видео (он разработал новую технику под названием NoGAN, чтобы поднять планку раскрашивания фильмов):
Джейсон — инженер-программист в Arrowhead General Insurance Agency, где занимается автоматизацией и обеспечением качества всего технологического стека. До работы в Arrowhead Джейсон работал синоптиком в Национальной гвардии ВВС Пенсильвании.
Излишне говорить, что я был взволнован, чтобы поболтать с Джейсоном для этого интервью Humans of Machine Learning (#humansofml). В этом посте мы рассмотрим, как именно работает DeOldify GAN, планы Джейсона по дальнейшему развитию DeOldify и его собственный путь к изучению науки о данных и глубокому обучению.
Мотивация DeOldify
Прежде всего, вы когда-нибудь восстанавливали фотографию вручную? Или с фотошопом?
До этого проекта я никогда не реставрировал фото. Мой опыт работы с Photoshop сводится к небольшому кадрированию здесь и там и случайному добавлению эффектов — например, как ребенок смешивает все газированные напитки вместе. Я вообще не искушенный пользователь.
Мне пришлось сделать это с помощью Photoshop на уроке фотографии в старшей школе. Это было очень кропотливо, но в то же время странно приятно. Были ли у вас какие-то особенные фотографии из вашей семьи или других мест, которые вы хотели восстановить?
Да, конечно! Когда в этом году мы с женой вернемся в Пенсильванию на Рождество, мы собираемся копаться в фотографиях, раскрашивать и восстанавливать. И мы не одиноки в желании сделать это — со мной постоянно связываются люди, обнаружившие мой проект в Интернете, и говорят, что хотят восстановить и раскрасить старые фотографии, которые у них есть, в частности, семейные. Я подозревал, что так оно и будет, но реакция на это была довольно необычной.
И мы не одиноки в желании сделать это — со мной постоянно связываются люди, обнаружившие мой проект в Интернете, и говорят, что хотят восстановить и раскрасить старые фотографии, которые у них есть, в частности, семейные. Я подозревал, что так оно и будет, но реакция на это была довольно необычной.
Итак, откуда у вас появилась идея DeOldify?
Некоторое время, еще до того, как я увлекся глубоким изучением, я думал, что вся концепция автоматического раскрашивания старых черно-белых фотографий была просто отличной идеей. Но казалось, что это никогда не делалось очень хорошо, даже с существующими моделями глубокого обучения. Летом, когда я проходил курс fast.ai по GAN (генеративно-состязательным сетям), я понял:
Причина, по которой черно-белое преобразование в цвет (и другие приложения глубокого обучения) не работает так же хорошо, как они могли, потому что человек все еще участвовал в ручном кодировании ключевого шага: оценки того, «хорошо ли выглядело» сгенерированное изображение.
 А.К.А. «функция потерь».
А.К.А. «функция потерь».Самый очевидный (и неверный!) способ оценить, создает ли нейронная сеть хорошее изображение, — это напрямую сравнивать пиксели и наказывать их в зависимости от того, насколько они отличаются. Это просто побуждает нейронную сеть быть очень консервативной в своих прогнозах: зеленый для травы/деревьев (это легко!), синий для неба (легко!), кожа для… кожи (легко!)…. и затем коричневатый для все остальное он просто не знает наверняка. Коричневый в числовом отношении является очень средним цветом, поэтому будет хорошей ставкой, если вашей сети рекомендуется просто минимизировать отклонения от ожидаемых значений пикселей.
Вот как выглядит эта тусклость:
Обучающие изображения, раскрашенные только с потерей восприятия — коричневый, как правило, является «безопасным» цветом по умолчанию. поэкспериментируйте с предсказаниями цвета. Но мне все еще кажется довольно хакерским делать это таким образом.
В противоположность этому, GAN эффективно заменяет эту закодированную вручную функцию потерь сетью — критиком/дискриминатором, — которая изучает все эти вещи для вас и учится скважина . Так что казалось несложным пойти по пути GAN, чтобы решить проблему реалистичной раскраски !
Так что казалось несложным пойти по пути GAN, чтобы решить проблему реалистичной раскраски !
Изображение, раскрашенное DeOldify: «Впервые смотрю телевизор в Лондоне, 1936 год»
В чем разница между раскраской и реставрацией?
Теперь мне немного смешно от того, что я просто пошел дальше и использовал два термина в описании моего проекта, не уделяя внимания определениям. Проще говоря, раскрашивание в моем представлении для этого проекта — это просто преобразование фотографий из монохромных в правдоподобные цвета, независимо от недостатков изображения, таких как выцветание и тому подобное. Нейронные сети прекрасно справляются с неверными/неполными данными, поэтому цвет можно успешно добавлять, даже если фотографии в плохом состоянии. Обратите внимание, что я говорю «правдоподобное окрашивание», потому что раскрашивание — это «неограниченная» задача. То есть для многих вещей (например, для одежды) не существует единого правильного цвета. Таким образом, я думаю, раскрашивание можно назвать «искусством», и, вероятно, поэтому так сложно заставить нейронную сеть делать это хорошо.
Таким образом, я думаю, раскрашивание можно назвать «искусством», и, вероятно, поэтому так сложно заставить нейронную сеть делать это хорошо.
Изображение, раскрашенное DeOldify: «Whirling Horse, 1898»
Реставрация в рамках данного проекта — это дальнейший шаг в попытке правдоподобно заменить детали там, где они отсутствуют/повреждены. Для меня самая распространенная проблема, которую я вижу со старыми фотографиями, заключается в том, что они выцветшие, поэтому моя первая цель — создать еще одну нейронную сеть, «отменяющую» выцветание. Однако это также было бы чем-то вроде «искусства» со стороны нейронных сетей, потому что опять же это немного неограниченная проблема — кто знает, что там было , когда ты его не видишь!
Изображение раскрашено (в центре), а затем обесцвечено (справа) с помощью DeOldify
Что касается раскрашивания и восстановления, я думаю, что работа выполнена, когда человек смотрит на полученное изображение и не может сказать, что изображение было обработано в первое место, или если они испытывают удовольствие, просто глядя на это! Я действительно считаю это искусством.
Это два отдельных процесса в вашей модели или они происходят одновременно?
Теперь это два отдельных процесса. Изначально я пытался их комбинировать, но оказалось, что это сложнее тренировать, и это просто не сработало. На самом деле это повторяющаяся тема в этом проекте — разделение отдельных функций с обучением/моделированием кажется более эффективным. Например, это противоречит здравому смыслу, но я получил намного лучшие результаты, когда перестал пытаться заставить критика оценить все сразу. Разделение этой проблемы на две отдельные части: 1. «Имеет ли изображение черты исходной градации серого» (потеря восприятия) и 2. «Выглядит ли это изображение реалистично» (потеря критики), сработало намного лучше.
Технический обзор DeOldify
Как именно работает DeOldify?
1. Большие данные!
2. ???
3. Прибыль!
Я шучу, шучу! Итак, у вас здесь две модели: Генератор и Критик.
Генератор — это то, что обычно называют U-Net. Чтобы уточнить, что такое U-Net — в основном это две половины: одна выполняет визуальное распознавание, а другая выводит изображение на основе функций визуального распознавания.
В этом случае U-Net, который я использую, представляет собой Resnet34, предварительно обученный на ImageNet. То есть при первоначальном создании U-Net сразу же выигрывает от возможности распознавать объекты на изображениях. Другая половина этого генератора смотрит на то, что распознает магистраль, а затем на основе этого определяет, какие цвета использовать, в конечном итоге выводя все это в цветное изображение. Цель обучения генератора в этом случае состоит в том, чтобы сделать это цветное изображение зеркальным отображением входного изображения в градациях серого, за исключением того, что оно имеет цвет.
The Critic — это очень простая сверточная сеть, основанная на критике/дискриминаторе из DC-GAN, но с небольшими изменениями. Некоторые из модификаций заключаются в том, что пакетная норма удалена, а выходной слой представляет собой свертку вместо линейного слоя.![]() Он большой (широкий), но простой. Он просто учится брать входные изображения и присваивать им единую оценку того, насколько реалистично они выглядят.
Он большой (широкий), но простой. Он просто учится брать входные изображения и присваивать им единую оценку того, насколько реалистично они выглядят.
Ключевым волшебным ингредиентом здесь была адаптация к этим моделям нескольких новых трюков из бумаги ГАН «Самовнимание». По сути, все, что я сделал, это поместил новый слой «внимания», который они предложили как в критике, так и в генераторе, а также спектральную нормализацию для обоих. Я также использовал их потерю шарнира и разные скорости обучения (правило обновления двух временных масштабов) для критика против генератора. Но это действительно сделало тренировку намного более стабильной. Кроме того, слои внимания действительно имели большое значение с точки зрения постоянства окраски и общего качества.
Изображение, раскрашенное DeOldify: «Интерьер фонтана с содовой «Миллер и сапожник», 1899 г.» и 256х256. На самом деле это было ответом на реальные проблемы, с которыми я столкнулся, пытаясь обучить модель только одному размеру — раскрашивание реальных фотографий либо просто не выглядело так хорошо, либо полностью глючило и не выглядело как исходное фото. Поэтому я представил режим обучения с прогрессивным размером, вдохновленный статьей «Прогрессивное выращивание GAN». Но большая разница здесь в том, что я не добавляю слои постепенно по мере увеличения размера тренировочного изображения — я просто настраиваю скорость обучения по мере того, как происходят переходы к большим размерам, так что переходы не взрываются, и модель в конечном итоге учится, как эффективно иметь дело с большим размером.
Поэтому я представил режим обучения с прогрессивным размером, вдохновленный статьей «Прогрессивное выращивание GAN». Но большая разница здесь в том, что я не добавляю слои постепенно по мере увеличения размера тренировочного изображения — я просто настраиваю скорость обучения по мере того, как происходят переходы к большим размерам, так что переходы не взрываются, и модель в конечном итоге учится, как эффективно иметь дело с большим размером.
Теперь давайте попробуем задать тот же вопрос, но в стиле ELI5 в стиле Reddit «Объясни, как будто мне пять».
Вызов принят! Итак, есть две вещи, которые работают для создания образов — генератор и критик. Генератор знает, как распознавать объекты на изображениях, поэтому он может взглянуть на черно-белое изображение и выяснить, какие цвета следует использовать для большей части объектов на изображении. Если он не знает, он изо всех сил старается выбрать цвет, который имеет смысл. Он изо всех сил старается сделать изображение реальным, потому что тогда критик посмотрит и попытается понять, настоящее оно или нет. Генератор постоянно пытается обмануть критика, заставив его поверить в то, что изображения, которые он создает, реальны. Так что это должно быть креативно — например, одежда не может быть коричневой! В противном случае критик быстро сообразит, что изображения, созданные с коричневой одеждой, фальшивые, и генератору не удастся обмануть критика. Генератор и критик продолжают улучшаться от этого друг к другу, и поэтому изображения становятся все лучше и лучше.
Генератор постоянно пытается обмануть критика, заставив его поверить в то, что изображения, которые он создает, реальны. Так что это должно быть креативно — например, одежда не может быть коричневой! В противном случае критик быстро сообразит, что изображения, созданные с коричневой одеждой, фальшивые, и генератору не удастся обмануть критика. Генератор и критик продолжают улучшаться от этого друг к другу, и поэтому изображения становятся все лучше и лучше.
Изображение, раскрашенное DeOldify: «Париж 1880-х»
Что такое генеративно-состязательная сеть?
Думаю, лучшее определение, которое я слышал, это две модели — генератор и критик/дискриминатор. Они конкурируют друг с другом так, что генератор постоянно пытается одурачить критика, а критик постоянно пытается не быть одураченным. Вы получаете действительно хорошие результаты в таких вещах, как генерация изображений, в этой настройке из-за этой конкурентной (состязательной) динамики.
Почему вы использовали GAN для этого проекта?
Это была простая интуиция: GAN эффективно изучает функцию потерь для вас. Прогресс в машинном обучении, кажется, делает огромный скачок, когда вы заменяете ручное кодирование машинным обучением. Например, распознавание изображений совершило огромный скачок несколько лет назад, когда функции кодировались таким образом, чтобы их можно было изучать снизу вверх, а не разрабатывать вручную.
Прогресс в машинном обучении, кажется, делает огромный скачок, когда вы заменяете ручное кодирование машинным обучением. Например, распознавание изображений совершило огромный скачок несколько лет назад, когда функции кодировались таким образом, чтобы их можно было изучать снизу вверх, а не разрабатывать вручную.
В начале изучения глубокого обучения я заметил, что мы все еще вручную кодируем функцию потерь. Это просто казалось явно плохой идеей! Итак, я только что пришел к выводу: давайте заменим закодированную вручную функцию потерь на GAN. Эта идея в моей голове была не только для этой работы по раскрашиванию: я думаю, что это действительно то, что, вероятно, направит будущие усилия и на другие вещи. Это просто имеет смысл. В случае раскрашивания концептуально не было большого скачка от генерации шума к изображению (большинство существующих GAN) к генерации изображения к изображению, так что это помогло. Но я действительно думаю, что вся эта общая идея об обучении машины функции потерь действительно мощная и важная.
С какими самыми большими проблемами вы столкнулись при разработке этого проекта?
Честно говоря, я (LOL) — Битва внутри моей головы и я держу себя на правильном пути. Я не был очень дисциплинирован в том, как я подошел к проекту, в основном потому, что я был так взволнован этим. Я постоянно был в сверхъестественной долине «это почти работает!» около двух месяцев. И поэтому я просто продолжал крутить ручки (вероятно, повторяясь), надеясь, что «вот оно!» Думаю, я провел около 1000 экспериментов, хотите верьте, хотите нет. Я действительно сделал много глупых ошибок просто потому, что не был осторожен и выстрелил себе в ногу из-за того, что из-за этого пришлось выполнять дополнительную отладку.
Ради забавы я проиллюстрирую некоторые из своих глупых ошибок в картинках!
Во-первых, я не удосужился визуализировать свои тренировочные картинки (после аугментации). Поэтому, когда я увидел странное размытие, происходящее ниже, я действительно сначала понятия не имел, что это было из-за того, что я вращал изображения и в результате терял детали — по сути, говоря сети сделать фотографии хуже.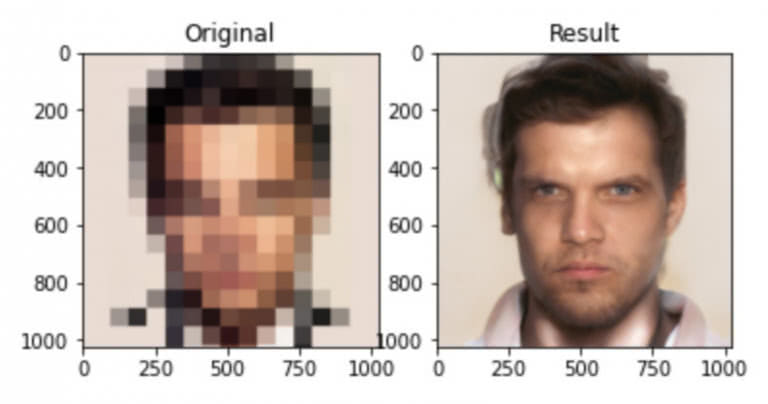 Прежде чем я понял это, я строил теории о том, что модель генератора почему-то работает не совсем правильно. Это было глупо! После того, как я настроил TensorBoard, в этом отношении все пошло намного проще.
Прежде чем я понял это, я строил теории о том, что модель генератора почему-то работает не совсем правильно. Это было глупо! После того, как я настроил TensorBoard, в этом отношении все пошло намного проще.
Размытое созданное тренировочное изображение, вызванное добавлением изображений с поворотами, что привело к потере точности изображения.
Во-вторых, я забыл запустить режим eval() при создании визуализаций, что привело к странным насыщенным изображениям. Мне потребовалось немного больше времени, чтобы понять это, чем я хотел бы признать…
Созданное тренировочное изображение перенасыщено из-за невозможности запустить визуализацию в режиме оценки Pytorch.
Третье — у меня, к сожалению, нет изображения этого, но довольно долгое время в начале проекта я был сбит с толку, когда получал несколько сгенерированных изображений, которые отражали бы каждую сторону посередине. Не всегда. Иногда. Это действительно выглядело странно. Оказывается, я загружал исходные изображения, которые были односторонними, но в половине случаев целевое цветное изображение было увеличено, чтобы быть перевернутым по горизонтали. Нейросеть решила, что лучшим решением для этого будет показывать каждую сторону с обеих сторон (попробуйте только представить!)
Нейросеть решила, что лучшим решением для этого будет показывать каждую сторону с обеих сторон (попробуйте только представить!)
В общем, главный урок здесь заключался в том, что мне нужно вернуть дисциплину разработки программного обеспечения, к которой я обычно так привык — получать быструю обратную связь, вносить сразу только небольшие изменения, внимательно читать код и тестировать, прежде чем перейти к новые изменения. Сначала я ничего из этого не делал, потому что был очень взволнован и нетерпелив. Это было неразумно.
Мне также пришлось бороться со всем этим «синдромом самозванца», когда у меня в голове постоянно крутится диалог, который выглядит примерно так:
«Чувак, месяц назад ты закончил курсы fast.ai, и это твой первый проект. Вы действительно думаете, что собираетесь сделать что-то настолько амбициозное? Вы явно заблуждаетесь».
После нескольких недель неудач очень легко начать в это верить. Даже после того, как я, наконец, добился успеха, мне потребовалось некоторое время, чтобы признать: «О да… Я действительно сделал здесь что-то важное!»
Вспоминая вышесказанное, я немного забавляюсь, потому что, прежде всего, в моей повседневной работе одна из самых важных вещей — дисциплина в разработке (тестирование, проверка кода и т. д.). И я тот, кто внушает подопечным на работе всю проблему «синдрома самозванца». Но с этим проектом все пошло прахом. Это был действительно хороший опыт для самопознания!
д.). И я тот, кто внушает подопечным на работе всю проблему «синдрома самозванца». Но с этим проектом все пошло прахом. Это был действительно хороший опыт для самопознания!
Давайте углубимся в данные вашего проекта, который часто является самой сложной частью проекта глубокого обучения. Что вы можете рассказать нам больше об этом процессе?
О боже… Ненавижу это признавать, но в данном случае мне не пришлось слишком много думать об этом! Первый набор данных, который пришел на ум, был ImageNet, и… он просто работал. Он пришел на ум, потому что он огромный и очень разнообразный (1000 категорий). Это в основном то, что мне нужно здесь, чтобы хорошо потренироваться в том, как раскрашивать.
В какой-то момент я попытался добавить набор данных Google Open Images, который действительно огромен и действительно разнообразен. Но на самом деле это не имело большого значения, и позже я также понял, что на самом деле там было несколько черно-белых фотографий, что не помогло. Так что я отказался от этого.
Так что я отказался от этого.
Как узнать, близки ли цвета к реальным? Похоже, что DeOldify может решить покрасить старую фотографию Белого дома в приятный светло-бирюзовый цвет. Это имеет значение?
Для меня имеет значение только то, беспокоит ли это вас как зрителя конечного результата. На самом деле я не ожидал, что Белый дом станет светло-бирюзовым, потому что его просто нет в палитре зданий, вообще говоря, и модель определенно улавливает, какие цвета «разумны» для данного типа объекта. Теперь, что беспокоит меня и беспокоит многих людей, так это то, что у модели определенно есть уклон в сторону синей одежды. Не вся одежда окрашивается моделью таким образом, но это определенно странная предвзятость. Это важно для меня, потому что это делает результаты менее правдоподобными.
Изображение, раскрашенное DeOldify: «Бедность в Лондоне, 19 век». Синий цвет, вероятно, используется здесь слишком часто, чтобы в это можно было поверить.
Так как же узнать, действительно ли цвета близки к реальным? Это зависит от того, о чем вы говорите, но многие вещи просто по своей сути «непринужденны» (опять же, как одежда), так что вы просто не знаете! И я чувствую, что это нормально, потому что раскрашивание действительно является для меня искусством.
Изображение, раскрашенное DeOldify: «Ah-Weh-Eyu (Pretty Flower), коренной американец Сенека, 19 лет.08”
Извлеченные уроки и следующие шаги для DeOldify
Какие самые большие сюрпризы при создании DeOldify?
Во-первых, то, что не сработало, стало для меня неожиданностью: я действительно думал, что GAN Вассерштейна — это то, что нужно (у них хорошие теоретические свойства). Но они были такими нестабильными. Я продолжал получать сумасшедшие изображения, такие как это:
Учебное изображение, сгенерированное из неудачной попытки использовать Wasserstein GAN для раскрашивания изображений
Думаю, это можно назвать искусством, и я действительно думаю, что это круто выглядит, но это определенно не то, что я искал!
В итоге я боролся с ГАН Вассерштейна в течение 6 недель, прежде чем, наконец, разочаровался в них и дал шанс ГАН с самостоятельным вниманием. Я быстро реализовал это, ушел и развлекал семью в городе, а затем, проснувшись на следующий день, обнаружил, что это действительно работает очень хорошо. Я не ожидал, насколько хорошо это работает, до такой степени, что я действительно беспокоился о том, что я, должно быть, смотрел на реальные цветные изображения на Tensorboard, а не на сгенерированные. Затем я подтвердил, что на самом деле да, модель действительно работает так хорошо!
Я не ожидал, насколько хорошо это работает, до такой степени, что я действительно беспокоился о том, что я, должно быть, смотрел на реальные цветные изображения на Tensorboard, а не на сгенерированные. Затем я подтвердил, что на самом деле да, модель действительно работает так хорошо!
Один результат особенно запомнился мне. Было так:
Изображение, раскрашенное ранней версией DeOldify: «Эвелин Несбит»
Теперь видно, что на картинке есть огрехи. Зеленоватый большой палец, например, и рука зомби, которая идет с ним. Но именно чашка меня взволновала. «Посмотрите, как он прорисовывает детали на этой чашке!» Я был уверен тогда, что я был на что-то.
В общем, самым большим сюрпризом было то, что он работал так же хорошо, как и работал. Это действительно не было моей целью здесь. Я думал, что получу лучшие цвета и в целом более реалистичные изображения, но детали, которые заполняются, поражают меня.
Каким вы видите DeOldify?
Я считаю, что мне невероятно повезло, что я соединил несколько точек и, по-видимому, получил современную автоматическую раскраску на основе GAN раньше, чем кто-то другой. Я убежден, что это было неизбежно — в конце концов, в этой области есть куча умных людей, так что… да… я сорвал джекпот «в нужном месте, в нужное время».
Я убежден, что это было неизбежно — в конце концов, в этой области есть куча умных людей, так что… да… я сорвал джекпот «в нужном месте, в нужное время».
Но я думаю, что есть много действительно крутых технических демонстраций, созданных множеством блестящих людей, и это только одна из них. И давайте проясним это — сейчас этот проект — просто крутая техническая демонстрация. Даже для Joe L33t Hacker вряд ли получится запустить и запустить это, потому что настройка — это просто большая проблема. Плюс требования к оборудованию через крышу.
Чего я действительно хочу, так это сосредоточиться на том, чтобы превратить эту классную техническую демонстрацию во что-то действительно практичное и полезное. То есть:
- Его легко запустить (не только в Linux)
- Легко установить (или вообще не устанавливать)
- Аппаратные требования снижены на несколько ступеней
- Образы не нужно «художественно подобранный», чтобы хорошо выглядеть
Это потребует много работы! Но я думаю, что именно здесь такие люди, как я (инженеры-программисты), хорошо проведут время в глубоком обучении. В отличие от погони за техдемонстрацией за техдемонстрацией.
В отличие от погони за техдемонстрацией за техдемонстрацией.
Вы пользовались библиотекой fastai — как это было? Вы рекомендуете это?
Я искренне рекомендую не только библиотеку fast.ai, но и курсы. Джереми Ховард и Рэйчел Томас проделали действительно замечательную работу по преодолению барьеров на пути к глубокому обучению. Они буквально изменили мою жизнь.
Самое замечательное в библиотеке fast.ai то, что она создана для того, чтобы ее можно было разобрать и собрать по кусочкам, чтобы она соответствовала именно той проблеме, которую вы пытаетесь решить. Он без проблем работает с PyTorch, и вы можете использовать fast.ai столько, сколько хотите. В случае с этим проектом GAN в библиотеке, по общему признанию, отсутствовала явная поддержка многих вещей, поэтому мне пришлось собирать части самостоятельно. Но в fast.ai по-прежнему есть много полезных многоразовых частей, которые я добавил, которые облегчили жизнь, и мне не пришлось изобретать их заново. Не все библиотеки такие.
Не все библиотеки такие.
Является ли ваш проект общедоступным для воспроизведения?
Это точно! Весь исходный код и даже изображения, которые я публикую в качестве примеров, можно найти здесь, в репозитории Github: https://github.com/jantic/DeOldify/blob/master/README.md
Совет для изучающих AI
Вы явно учитесь всю жизнь. Чему вы надеетесь научиться или заняться дальше в своей карьере?
Ну, это немного забавно – я получил все это внимание из-за этого самый первый проект Я сделал сразу после того, как мои уроки fast.ai были закончены. Предполагалось, что это будет только первый из многих проектов, охватывающих различные подходы к глубокому обучению (зрение, структурированные данные, обработка естественного языка и т. д.). И я все еще хочу это сделать, потому что кажется, что «перекрестное опыление» идей в глубоком обучении имеет большую ценность. Например, Джереми Ховард создал современную nlp (ULMFiT), адаптировав основную идею «переносного обучения», которая к тому времени была легкой задачей в компьютерном зрении. Видимо это не было легкой задачей в nlp до ULMFiT, что меня удивляет. Я хочу быть в поиске таких возможностей, и я думаю, что принятие более широкого взгляда на вещи поощряет такие ментальные связи.
Видимо это не было легкой задачей в nlp до ULMFiT, что меня удивляет. Я хочу быть в поиске таких возможностей, и я думаю, что принятие более широкого взгляда на вещи поощряет такие ментальные связи.
Это немного второстепенно, но я также верю в то, что навыкам решения проблем можно научиться и что они могут продвинуть вас гораздо дальше, чем просто интеллектуальные способности. Это моя большая страсть. Я надеюсь начать излагать эти идеи в каком-нибудь блоге.
Какой-нибудь совет для тех, кто хочет начать работу с глубоким обучением?
Я думаю, что хочу рассмотреть это с точки зрения разработчика программного обеспечения, который работает в этой области уже несколько лет и жаждет перемен. Вот к чему я пришел, и я столкнулся с несколькими препятствиями, прежде чем почувствовал, что наконец понял это правильно.
Во-первых, это большие затраты времени. Сначала я думал, что смогу заниматься этим вечером после работы, и в результате у меня было несколько фальстартов. Вы можете увидеть эту печальную историю в моем репозитории на Github нескольких разветвленных курсов глубокого обучения за годы, которые ни к чему не привели. Летом 2017 года я попробовал пройти первую итерацию курсов fast.ai. Хотя мне это нравилось, и я был убежден, что должен продолжать это делать (и мог бы это сделать в первую очередь!), я также заметил, что просто не могу тратить столько времени, сколько мне нужно, чтобы действительно получить хорош в этом и не сгореть полностью.
Вы можете увидеть эту печальную историю в моем репозитории на Github нескольких разветвленных курсов глубокого обучения за годы, которые ни к чему не привели. Летом 2017 года я попробовал пройти первую итерацию курсов fast.ai. Хотя мне это нравилось, и я был убежден, что должен продолжать это делать (и мог бы это сделать в первую очередь!), я также заметил, что просто не могу тратить столько времени, сколько мне нужно, чтобы действительно получить хорош в этом и не сгореть полностью.
Я собираюсь немного поэкспериментировать, но дело в том, что у нас не так много часов в сутках, но, похоже, культура программного обеспечения не полностью приняла эту реальность в том, что касается ожиданий относительно того, как вы тратите ваше время. Мы все хотим всего — быть здоровыми, иметь друзей, быть отличным работником, быть хорошим мужем, учиться всю жизнь и т. д. Но в сутках не так уж много часов.
Вы не можете иметь все это. Вы должны сделать трудный выбор и выделить значительное количество времени, чтобы сделать это правильно.
Итак, чтобы заставить это стремление к глубокому обучению работать на себя, я на самом деле договаривался о неполной занятости на своей основной работе и ждал еще год (лето 2018), прежде чем я, наконец, сделал решительный шаг. Но наличие этого дополнительного времени изменило все в моем сознании. Вот почему мне было удобно «тратить» целых два месяца на проект (много часов!!), который, честно говоря, оказался довольно крутым. Эта слабина, встроенная в график, позволила творчеству идти своим чередом.
Какие ресурсы вы бы посоветовали людям проверить?
Если вы действительно хотите погрузиться в глубокое обучение, я думаю, что несколько высококачественных ресурсов выделяются:
- fast.ai (не могу выразить достаточно любви к этому)
- Нейронные сети и глубокое обучение онлайн книга: Полная отличных интуитивных объяснений и отличное дополнение к fast.ai
- Distill: Как только вы продвинетесь по первым двум, этот сайт станет просто удовольствием для чтения и взаимодействия. Это отличная инициатива, и я надеюсь, что в ближайшее время по ней будет опубликовано больше материалов.
- FloydHub: сверхинтуитивная платформа для запуска и работы на облачных графических процессорах, вместо того, чтобы беспокоиться об образах Docker, настройке среды и DevOps ресурсы — это может сыграть решающую роль в обучении, мотивации и т. д.
Это было здорово! Спасибо, Джейсон, что поболтал со мной. Куда люди могут пойти, чтобы узнать больше о вас и вашей работе?
Проект DeOldify находится здесь, на GitHub. И еще больше я говорю об этом в Твиттере.
Кроме того, если вы хотите узнать больше об исследованиях Deoldify, вы можете посмотреть эту презентацию, размещенную на F8:
Спасибо за интервью! На самом деле это побуждает больше людей изучать глубокое обучение.
Я думаю, что мы только коснулись потенциала не только для решения проблем, но и для открытия новых возможностей для творчества.GFP-GAN — это новый бесплатный инструмент искусственного интеллекта, который может мгновенно исправить большинство старых фотографий считанные секунды, и он может сделать это бесплатно.
Любой, у кого есть старые фотографии своих родных и друзей, которые плохо сохранились со временем, независимо от небольшого и/или плохого состояния изображения, теперь имеет возможность восстановить свои выцветшие и потрескавшиеся изображения, вернув их в первоначальное состояние. их исходное состояние или даже лучше.
В приведенном выше восьмиминутном видео от What’s AI Луи Бушар описывает, насколько хорошо проект «На пути к восстановлению слепых лиц в реальном мире с помощью генеративного априорного лица» (опубликованный в марте 2022 г.) работал над восстановлением фотографий, с подробным описанием того, как используйте его бесплатно.
По словам Бушара, модель ИИ работает даже с файлами очень низкого качества и низкого разрешения, но все же может превосходить многие другие инструменты ИИ для восстановления фотографий, обеспечивая невероятные результаты. Хотя восстановленные изображения впечатляют, Бушар говорит: «Они не отражают реальное изображение. Важно понимать, что эти результаты — всего лишь догадки модели — догадки, которые кажутся чертовски близкими.
«Человеческим глазам это кажется одним и тем же изображением, представляющим человека. Мы не могли догадаться, что модель создала больше пикселей, ничего не зная о человеке».
Улучшенная версия 1.3 модели GFP-GAN пытается проанализировать содержимое изображения, чтобы понять его содержимое, а затем заполнить пробелы и добавить пиксели в отсутствующие участки. Он использует предварительно обученную модель StyleGAN-2 для ориентации собственной генеративной модели в нескольких масштабах во время кодирования изображения вплоть до скрытого кода и вплоть до реконструкции.
Использование дополнительных показателей помогает ИИ улучшать детали лица, фокусируясь на важных локальных особенностях, таких как глаза, рот и нос человека. Затем система сравнивает реальное изображение с вновь восстановленным изображением, чтобы увидеть, есть ли на сгенерированной фотографии один и тот же человек.
GFP-GAN не лишен недостатков. По словам разработчиков, хотя восстановленные изображения намного более детализированы, чем предыдущие и другие версии, текущие восстановленные изображения не очень четкие и могут иметь «небольшое изменение идентичности». Это означает, что в некоторых случаях восстановленные изображения могут иногда выглядеть как другой человек. Обычно это чаще происходит с изображениями с очень низким разрешением и очень сильно поврежденными, поэтому ИИ приходится делать некоторые предположения относительно того, что скрывается за размытыми или рваными участками фотографии.
Бушар говорит, что, несмотря на то, что результаты в основном фантастические и удивительно близки к реальности, «полученное изображение будет выглядеть так же, как наш дедушка, если нам повезет.
 Это отличная инициатива, и я надеюсь, что в ближайшее время по ней будет опубликовано больше материалов.
Это отличная инициатива, и я надеюсь, что в ближайшее время по ней будет опубликовано больше материалов. Я думаю, что мы только коснулись потенциала не только для решения проблем, но и для открытия новых возможностей для творчества.
Я думаю, что мы только коснулись потенциала не только для решения проблем, но и для открытия новых возможностей для творчества.

